
I was traveling most of last week and so was unable to weigh in on the Web 3.0 mini-tempest that occurred when John Markoff published his exploratory piece in the NY Times last Sunday. The premise of the article is that we are finding new ways to mine human intelligence which can be exploited by building a new layer of “meaning” on top of the accumulating mass of global collective intelligence that is growing by leaps and bounds every day on the Internet. Collective intelligence of course is one key aspects of Web 2.0, namely an Internet that is continually improved by constant and sustained contact with hundreds of millions of users contributing content. These users can either contribute explicitly via a conscious act or implicitly by their very interaction with the Web which then leaves behind useful behavioral “tracks” that can be fed back into the system. In this ways, hundreds of millions of people are adding to what we know every day, even if individuals contributions are often minor.
Markoff’s description of Web 3.0 was ostensibly prompted by something I’m seeing as well, well beyond pure play Web mashups we’re beginning to witness a number of companies building end-user solutions that can automatically navigate the Internet, weave together tapestries of online information to generate new, useful results. They can even take it a step beyond: dynamically generated situational Web applications that fully interact with the Web ecosystem. Such applications — self-assembled by these tools — can perform useful tasks such as planning vacations, managing personal schedules, or even orchestrating complex, collaborative business processes for example including entire real-world projects. The vision is stunning and futuristic yet and the rich fabric of the Web today, with hundreds of open APIs and even vaster reservoirs of content and raw data, now opens the door to the possibility.
Background Reading: Take a look at eight end-user mashup platforms available today
I’ve written a lot recently about the trend of user generated software, applications developed by end-users that use the openness of the Web 2.0 era to interact with high value Web services. But already we’re beginning to see the emergence of the next step beyond that: applications developed and tasks completed intelligently by software itself. Tim-Berners Lee himself envisioned this as the coming Semantic Web which he brilliantly espoused in Scientific American a few years back and has been the goal of great many companies ever since, but which has been relatively unsuccessful on a large scale even up until now. The reasons for this are complex but seem to lie in what we learned from Web 1.0; a priori solutions often aren’t the right ones, emergent ones are .
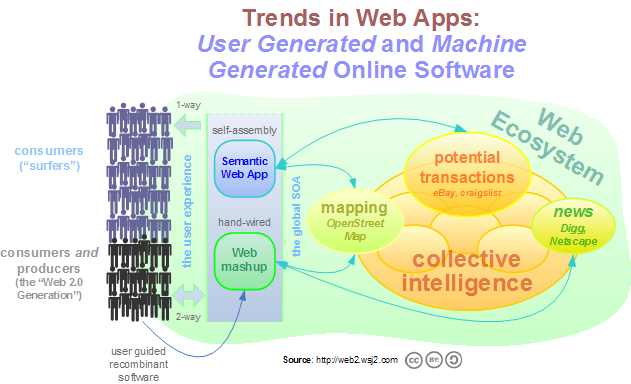
So while many might say that the 1,200+ mashups currently listed in the trend graphs on Programmable Web are mostly NOT user generated, one only has to look at the widespread use of badges and widgets on MySpace and other major social networking sites to see that everyday people are getting more and more comfortable with “turfing” their blogs and spaces with content, code, and feeds from elsewhere on the Web. So while much of the end-user mashup activity we see today is probably shallow and don’t represent sophisticated functionality, the new tools we’re seeing every day are getting better and better and allowing users to take it deeper, creating a true mashup ecosystem.
The shortage of developers and application backlogs: Not finding the app you need
Here’s an significant fact, if you look at the number of professional software developers out there today, they are dwarfed by the number of end-users with the time and motivation to describe the solutions that they need. And interestingly, the same population is dwarfed by the potential output of computer systems that can be directed to create the applications or carry out the tasks we need, with minimal continuous attention on our part.
If you only look at the enterprise IT space you will see that users usually have a long list of things for which they’d like software solutions, but can’t get satisfied by the traditional purchase or build processes in place in most organizations. Every CIO out there is painfully aware of this application backlog but hasn’t had the tools to address it. And out on the Web, there’s a different problem: Lots of Web sites, but little software that will do the specific things that a users needs to get accomplished. As Steve Borch says , “sit back, relax, and let your customers create your products.“
Like IBM is realizing with their exploration of end-user driven development products like QEDWiki, most of us today are already conducting much, if not most, of our software integration manually, by re-entering or cutting and pasting data endlessly between our applications. This implies that 1) there’s demand but not enough access to software that does exactly what people want and 2) there is a very low level of integration between the dozens of pieces of software that we currently use on a daily basis.
And in fact, there really is at least two ways for Semantic Web technologies (and its myriad offshoots, many of them proprietary) to improve the way that we use the Internet. The first is in fact to provide that “layer” of meaning; making the underlying intent services and content to be made clear to programs and not just developers. And the second is to actively exploit that layer; building software or carrying out processes intelligently on the behalf of users.
Traditional software isn’t adaptable enough: Mashups and Semantic Web Apps are a better way to do things on the fly
Need a piece of software to manage the process of planning a wedding and its long list of attendees, suppliers, and dependencies? How about something to coordinate the delivery of construction materials to a job site for the least total cost including materials and shipping, just in time and in the correct order as the items on the construction schedule are completed? The possibilities in the consumer and business worlds both are truly endless and reflect that such software can at long lat perhaps fill The Long Tail of IT software demand , which could never cost effectively serve the thousands of mass customized applications that would potentially make using software a dream instead of the chore that it often becomes due to the fact that processes and not just data is what needs to be managed.
And while this — and by “this” I mean recombinant, self-assembling software that exploits collective intelligence — is certainly the cutting edge of software development, many companies are beginning to map out this terrain closely and I encourage you to begin tracking them along with me. Startups and initiatives such as JackBe, Teqlo, OpenKapow, Itensil and a great many others are either wholly or partially enabling the automation of software creation and process management. Interesting, they are usually not via true Semantic Web technology, but by virtue of open, simple, easy-to-describe-and-consume services of the Web 2.0 generation .
This brings us to my last point. In a panel earlier this year with Adam Bosworth and other notably Web lumuniaries, I responded to an audience question about the difference between Web 2.0 and the Semantic Web by saying “Web 2.0 is what happened while we were waiting for the Semantic Web.” And that highlights an interesting point, that this latest generation of tools appears to be built on simple yet proprietary approaches and not on the open but formal Semantic Web technologies. Whether this points to underlying issue with the usability of Semantic Web 1.0 is hard to say but RSS 1.0 ran into the same issue. Thus I call this next generation of approaches the “Pragmatic Semantic Web.” But I am a bit concerned about the lack of standards and this will be something to watch as we see if this next generation of online software is truly ready to sprout wings and fly.
What other Web 3.0/Pragmatic Semantic Web companies or projects do you know about?